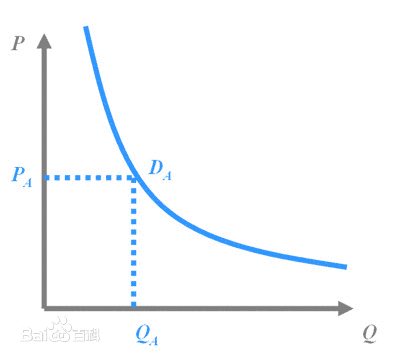
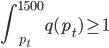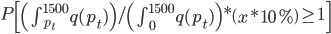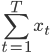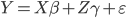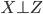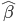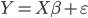前段时间COS上说Rafael Irizarry用最小二乘法帮小朋友玩乐高,已经觉得很出手不凡了。然后今天直接看到了ev3dev.R这个东西,瞬间觉得整个人都不好了...大家要不要这么geek...
这种恶意卖萌的对话什么的实在是...总而言之,这货已经开始被进化了...
SER: Tell us more about the R part.
SERATRON: I am running RServe server. PCs can communicate with me using RSclient. They do all the heavy computations for me, I can’t be bothered (I have no FPU, can you imagine?!?). Those PCs think they can command me…SER: Why do you have two servo motors?
SERATRON: So that I can move, you silly!SER: Hmm, why do you have an infrared sensor?
SERATRON: So that I can avoid obstacles and I will not fall from height. Why do you have eyes donkey?SER: Errrrrr, what are your touch sensors for?
SERATRON: They also prevent me from falling from height. If I don’t feel the surface below me I am not going to move. Would you?SER: Ok, last question you naughty robot! What is your gyroscope and accelerometer for?
SERATRON: Can’t you count? It’s not one question but two. I use gyro to know my heading direction. No dumbass, not for balancing, I don’t use it in this axis. I don’t use accelerometer now but I could use tilt input as a third level protection from falling. I could also use it to detect collisions with other objects but I have other means.SER: It was a pleasure to meet you (coughs), thank you.
SERATRON: I hope I will be finished for SER VII – 08.12.2014!

总而言之这货已经可以自我前进、躲避障碍什么的,为嘛我想起来的是我家那个扫地机器人iRobot 380t?

对了,卖萌视频在此:http://www.r-bloggers.com/interview-with-seratron-lego-ev3-robot-driven-by-r/