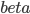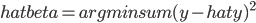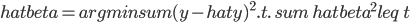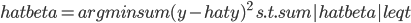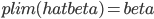感觉自己好就不说“文化差异”这个词儿了,有的时候毕竟只是个体差异没有必要非归根结底到文化上,不公平。可是有件事儿除了文化差异我实在想不出来别的词儿来解释了,那就是abortion,即中文的“堕胎”。
这学期在听labor economics,而其后半部分正是关于family economics的,所以我们就整体热火朝天的讨论堕胎等诸多事宜。我感觉(希望不是太离谱),在中国堕胎其实是很普遍很容易的,依稀记得原来在教室上自习的时候都能不时受到各种“无痛人流”的小广告卡,一打开报纸也都是类似的广告,可见这个产业有多么发达。所以我一直不觉得堕胎是件多么大不了的事儿,不过是无知少女付出的代价而已。没想到在这点上,西方反而比我们保守。这里面有宗教的原因,觉得堕胎是谋杀生命,尤其是在美国;还有健康的考虑,医生只在特定的某几个月对孕妇实施堕胎手术(西班牙当地的情况)。结果一讨论起堕胎,就看到周围同学的脸色煞然间严肃起来,只有我若无其事的夸夸其谈,然后还很天真的问“这在美国算个大事儿么?”,预期到同学们很无奈的回答我“要知道这东西在美国是一个极其敏感的话题”。哈哈,有点以此为乐的感觉。同样的还有避孕套这个东西,据说米国有些人是不用的,出于的是宗教的原因。想想国内这东西的承认度好像蛮高的,没听说啥宗教的考虑,也没啥传统文化的约束。说到堕胎,还想说一下中国的性解放……感觉上,中国在这个问题上特别矛盾,一方面是传统家族文化施加的压力下各种保守,以及有点极端的“处女情结”泛滥;另一面又是性教育的缺失,尤其是对于年轻少女们的保护远远不够,导致很多人根本意识不到堕胎的危害,只是一味的不肯承担后果。我想知道的是,如果她们知道“堕胎三次以上就会习惯性流产以至终身不孕”,那么还会这么伤害自己的身体吗?性解放如果只是行动意识上的解放,而不是教育上的解放,这恐怕会有点悲剧的色彩。某种程度上我还比较幸运,生物比别人学的多一些,所以从科学的层面了解的多一些;却也每每看到听到各种花季少女的故事,不禁感到遗憾和悲伤。
插一句很悲惨的事儿,最近development在讲国际贸易、生产力之类的东西,然后这老师好像格外偏爱中国似的,篇篇文章都以中国为例子。可怜我对这东西一点知觉都没有,上课的时候听的云里雾里的,问问题也问不出来,回答问题也没话可说,好像这里的“China”我不曾呆过似的,一点都没有熟悉的感觉。真的是上课倍感悲凉啊,看来我的宏观和国际经济学基础真的是差到一定程度了,连别人为什么研究TFP之类的东西都没有直觉,嗯……
然后突然想起来曾几何时看到过这么一句话,忘了是谁写的以及在哪里看到的了,作者很悲伤的感慨“我认识的很多做理论做得好的,做着做着就转计量了”,然后一片悲摧的神情几乎跃然纸上。我原来也是有点多多少少偏向modelling而不是empirical的,现在却多少改变了一些想法,实证的很多估计还是能给人带来很多直觉的。如果实证研究做得好的话,对于理论的贡献也是不可低估的。况且,计量还有计量理论本身是不是?那些天才相当于半个统计学家呢!原作者的理由大致是计量好出文章,所以很多人迫于生存压力就转行了。我就在想,计量某种程度上是好出文章,但是现在大家都玩到这个程度了,实证方面的经济学越来越有实验科学的倾向了,难道实验科学好出文章?没有那么简单吧。
最近也算自愿、也算无可奈何的要在一周内做两个research proposals,一个是关于sexual education的,大致是想看看如果通过社会网络进行性教育,会不会比传统的课堂教育效果更好,毕竟这东西这么敏感是不是;另一个是marriage market的,大致是整合一些心理学方面对于情侣配对的研究然后放在经济学里面,争取在 partner matching阶段做出一点有意义的解释。没办法,这俩东西都是for family economics的,所以逃不开这些话题。不过还算幸运,是跟两个group一起做,我的实际工作就少了很多,更多的是提提idea然后有人去写下来成正式的文章,嗯啊。某种程度上的轻松。关于sexual education那个,显然是要做实验了。然后我最近一直在跟同伴们强调的就是“如果我们在experimental design层面做的好一点,那么后面的计量分析会轻松许多”,这是在我突然间发现他们在research proposal的大纲上酣然列下了probit model之后惊出的一身冷汗。还没设计好实验呢,就开始考虑计量模型和那些fancy的方法了,晕。虽说实验不是万能的,但是我们总是可以尽力做的更理想一点,控制的更好一点,实在不能控制的再用identification strategy去弥补嘛!毕竟一旦到了计量上,就是一个“效率(efficiency)和一致性(consistency)的平衡”问题了。我是宁愿选择前期多做一点,后面可以让结果用相对简单的模型也能估计的很有说服力。
说到一致性,在我脑中往往的联系就是“统计上的因果关系”。计量的一大目的就是做"causal effect"估计,中文自然就是“因果推断”……不知为什么每次这么翻译的时候都小小的犹豫一下,觉得这四个字重若泰山。说具体一点,其实是统计上的因果推断。这个idea大概来源于生物实验,最有名的自然是孟德尔的豌豆基因的实验,想必大家高中生物课上都学过。这里不重复实验的细节了,想说的是那个实验提供了对于染色体、基因工作规律的直觉,后面科学家才能更进一步的挖掘其中的原因。这是一个很典型的统计推断做出巨大贡献的例子。然后计量上,尤其是在田野实验中,我们也跟科学家似的弄个实验组(treatment group)再弄个对照组(control group),然后控制一下随机分布就可以说是因果关系了(实验设计理想的话)?当然关于这个问题的争论还很多,一大批判来源于structural那边,大致就是说你只知道结果可能是这样,但是你不知道为什么会是这样,所以这实验能不能重复(internal validity),以及推广到其他情形有多大效果(external validity),都是未知的。当然,这个也得看你到底想得到什么了。对于政策制定者来说,很多时候并不需要知道这玩意儿到底为什么工作,只要知道这个政策能工作就好了。最简单的例子,我们作为一般电脑用户,大多数人并不知道电脑为什么会工作,不知道CPU是怎么处理0101这些二进制东西的,只要我能用Photoshop修个图、word排个文件就行了。所以有的时候,我对reduced form也不是那么的反感,有点实用主义的味道——看你想要什么了。
最后还有一点点想说的,就是赚钱和经济学的事儿。labor economics里面很关心教育回报的问题,其中就有很多人研究过各个大学专业与毕业后工资水平的问题。如果市场的选择是理性的话,那么从现在大学录取时候的分数线就可以看出,那些专业前景相对较好。当然,经济学首当其冲。不过“经济学”这个词儿看起来太过美妙,大到可以“经世济国”,最不济也可以养家糊口,所以很多家长就抱着美好的愿望毅然决然的把孩子送到经济学专业里面来了。其实本科的时候还好,相比于其他纯理科,经济学和现实应用的距离稍稍近一点,换句话说就是和市场脱轨的不是那么厉害。但是一旦到了学术那一面,其实啥子学科都是一样的,学术永远是和赚钱不是那么直接相关的。不知道这是一种科学家的清高,还是学术界和市场的本质目标不同。但是经济学依旧那么热……一个被“曲解”的绝佳例子就是Laffont的《激励理论》,明明是一本很技术性的委托代理模型的教科书,就是配上了这么一个模棱两可的名字,于是就被某些管理学MBA课程之类的拿去当作“员工激励”之类的东西去讲了……当然我不知道那些人是怎么演绎着这东西的,毕竟确实是有CEO等代理问题可以通俗化的解释,不过无论如何总是感觉怪怪的是不是?话说回来,相比于其他学科的不着边际,经济学还是稍稍好一点点的——我是说本科毕业生找工作的时候。所以,选专业的时候选经济学或许真的是市场理智选择的结果……
 挂了很多人的高树...
挂了很多人的高树... 良辰美景虚设
良辰美景虚设