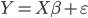嗯啊,自从著名的微观经济学家Varian跑到google兼职之后(话说Varian这厮最著名的八卦,就是自己在买新彩电之前,各种搜集数据建立模型,然后经过各种最优化选择了最佳时点入手...不就是买个电视嘛,至于这么学以致用嘛~),经济学帝国主义展露出其雄心勃勃的志向——无底线的渗透到各个行业各个环节。有的披着数量分析的外衣,有的带着策略决策的高帽,总之就是各种高端各种名正言顺。然后看看他们发出的paper嘛,什么呀,还是economists这群人自己的逻辑规则。哎呀呀~
最近看AEA系列的文章,发现了两位埋伏在互联网公司的大神,Justin M.Rao和David H. Reiley,貌似原来都在Yahoo!后来一个跑到了google一个投奔了Microsoft。然后这俩人还到处在econ期刊上面灌水,嗯嗯,小小谴责一下~你们又不评tenure神马的,干嘛总抢有限的publication资源啊(好吧其实这俩明明是过着我羡慕而暂时不可得的生活...)。
本来先看到的是这俩人发在JEP上的,关于垃圾邮件的:
Rao, Justin M., and David H. Reiley. 2012. "The Economics of Spam." Journal of Economic Perspectives, 26(3): 87–110.
然后顺藤摸下去,找到了俩人的网站(作为具有geek气质的经济学家,这俩人果然都有独立网站~),然后就看到了更多的papers:
The Good News-Bad News Effect: Asymmetric Processing of Objective Information about Yourself (local copy) (joint with David Eil AEJ Microeconomics July 2011
Here, There and Everywhere: Correlated Online Behaviors Can Lead to Overestimates of the Effects of Advertising (local copy) (joint with Randall Lewis and David Reiley). Proceedings of World Wide Web Conference 2011 Research Papers
嗯嗯,这两篇看起来也很有意思(对他们研究NBA的那些文章表示~米有兴趣)。这三篇中,最符合我现在的迫切需求的就是最后一篇——在线行为中的相关性与互联网广告效果评估。米办法,现在整天对着各种评估,各种错综复杂让人经常抓狂。还是看看文章舒服一点。
现在开始说一下最后这篇文章。记得刚刚到eBay的时候,就有被问到,“怎么从correlation到casuality?”。当然,呃,计量注重的因果推断只是狭隘的统计意义上的因果,不过还是比correlation有着实质进步的。因果推断的方法,嗯,很多,只要解决了内生性问题,什么都好说。那么,好吧,最simple and elegant的就是随机分组实验了,因为是随机,所以分组变量一定是外生的,所以估计了一定是一致的。然后就是根植IV理念的一系列方法,然后就是对付无法观测变量的panel data方法...时序我实在是不了解,所以这里就不知道了(最悲哀的是为什么总被问到时序的问题啊,个体的数据是多么好的面板分析base啊,为什么一定要损失信息弄成一些时序指标呢?)。
回到文章。一开始作者就提到了互联网广告效果评估的一个经典“相关行为偏差”案例:
案例1: 用户行为的相关性与估计偏差
Yahoo!在首页上为某大厂商展示了其品牌广告,之后评估由其带来的相关的关于该品牌的搜索行为。没有对照组的时候,他们使用用户在campaign开始前一个星期的各种浏览行为作为控制变量,然后发现campaign带来的提升效果约在871%到1198%之间,可谓 too good to believe。
然后大家就有疑虑了,作为一个经常访问Yahoo!的用户,自然相比于那些不怎么常来的人有更高的概率看到该广告(在线广告一般定义exposure,即被展现即作为treatment),而且他们作为资深用户更有可能去搜索一些关键词。这样,就出现了这两个变量的高度正相关——搜索却不是在线广告直接引起的,而是用户本身特性决定的。然后大家就会说了,那么干脆把campaign开始前用户的搜索行为也作为一个控制变量好了。但是这个东西实在是不稳定,每天之间波动实在是太大。
简单总结一下,就是被展现过广告的用户for sure会比那些没有展现的用户更活跃,所以本身就是一个selected sample,也没有很好的控制变量可以完全的消除这里的选择性样本问题。而在采用了随机对照试验之后,最终的估计量是5.4%,也就是说实际上直接由广告带来的相关搜索只有5.4%的提升量。
然后就有人说,哦,都是同一站点的行为嘛,自然可能相关性比较强。那么不同站点之间的行为,是不是行为之间的相关性就会比较弱一些呢?然后就不会这样干扰结果了?于是,作者进行了第二个实验。
案例2:网站之间交叉行为相关性
Yahoo!在Amazon上放了一段30秒的视频广告,以推销Yahoo的一项服务。然后他们发现,在接下来的一周之内,这些看到该广告用户的中,使用Yahoo!这项服务的用户大概提升到以前的3倍!可见这个广告是非常之有效啊!
然而有意思的是,在同样的时间段之内,另一组用户看到的是是一段政治广告。作为control group,这些用户对于该服务的使用量也差不多增加了2倍——也就是说,可能是其他的一些campaign或者用户的自然增长导致了活跃用户的增加,而不是直接的源于这段视频广告。对比之后,该广告的效果只能用“微乎其微”来形容了。
所以,不同网站之间的行为可能是高度交叉相关的,不能简单的忽略这种行为相关的可能性去采用一些简单的观测评估。否则,往往估计效果会大大的偏离实际。
案例3:广告会造福竞争对手?
一个在线服务商在Yahoo!上展示了2亿次广告,但是很可惜,Yahoo!无法追踪到该广告为服务商直接带来的用户转化量。不过“幸运”的是,在这段时间,他们追踪到了该服务商的一个竞争对手的新用户注册量。于是,“不幸”的结果发生了——看到广告的当天,用户更可能去注册竞争对手的网站用户。莫非,这段广告不仅仅让投放者收益,而且也造福了竞争对手?(比如促进了消费者对于一项新服务的认知度,我们习惯称之为正面的“溢出效应”)
还好,当时Yahoo!也设置了对照组,发现其实对照组的用户在这段时间之内也有很多人去竞争对手网站注册。所以其实这种溢出效应基本为零,不用担心啦~竞争对手用户数上升可能是与此同时其他促销或者广告行为的影响,与这段广告没什么关系的。
嗯,其实这篇paper本身米有什么technical的难度,稍稍学过一点本科计量经济学的应该都能顺利的看懂,不过几个案例还是蛮有说服力的。唯一稍稍遗憾的是,这篇文章的style还是太economist taste了,不是那么的符合业界人士的思维路径...
我想在此基础之上,稍稍多说几句关于“实验设计”的事儿。随机实验很简单的,解决了很多内生性相关性问题,是一个典型的“better data + simple method = better results"的例子。同样的,很多时候如果可能,提高数据的质量而不是寻求更复杂的模型,往往是解决问题最省力的办法。这里的数据质量不仅仅是说“除噪”这些基本功,而也包括数据是不是贴近分析目的设计和搜集的。去年写了一系列的“社会网络中的实验”,一直在说一个优雅的实验设计会带来多么优雅的分析。当然很多的时候,一些客观的现实问题导致实验也只能被优化到一个特定的层次。其实一直在想的是,连续的实验该怎么设计?
有的时候,因果关系不需要一次次的挖掘,实验也不需要每次都做,毕竟实验都是有成本的。如果能设计出来一系列优雅的实验,那么很多问题就可以一次性的干净利索的回答,不好么?不过既然在这里说到这些,说明日常的工作中还是存在很大改进余地的。嗯,有空间才有成长,挺好的~
p.s. 其他两篇papers也会稍后介绍~嗯嗯。
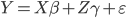 ,且
,且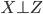 ,那么下面两式估计出来的
,那么下面两式估计出来的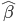 (均值)一致、估计方差后者小。
(均值)一致、估计方差后者小。