这节课主要是讲线性优化的对偶问题。感觉这东西貌似在运筹学的时候被折腾过一遍,现在又来了-_-||
附赠个老的掉牙的段子...
有人问经济学家一个数学问题,经济学家表示不会解...
然后那个人把这个数学问题转成了一个等价的最优化问题,经济学家立马就解出来了...
好吧,我还是乖乖的赘述一遍对偶问题吧,表示被各种经济学最优化问题折磨过的孩子这点儿真是不在话下。
--------------------------------------------------------------------
1. 对偶问题的一般情况
1) 优化问题
一个典型的最优化问题形如:
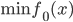
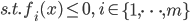 (不等式约束)
(不等式约束)
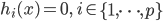 (等式约束)
(等式约束)
2) 优化问题的Lagrange (拉格朗日)函数
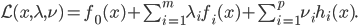
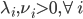
3) 对偶函数
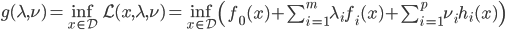 称为该优化问题的对偶函数。此时,
称为该优化问题的对偶函数。此时,
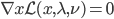 ,显然这个时候一阶偏导数为0。
,显然这个时候一阶偏导数为0。
4) 对偶问题
我们称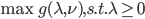 为原优化问题的对偶问题,可化为最优化问题的标准形式
为原优化问题的对偶问题,可化为最优化问题的标准形式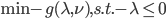 。
。
如果原优化问题为凸优化,则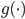 必为凹函数,从而最终的标准形式依旧是一个凸优化问题。
必为凹函数,从而最终的标准形式依旧是一个凸优化问题。
5) 弱对偶性
令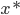 为原问题的解,则
为原问题的解,则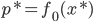 ,且
,且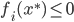 ,
,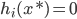 .
.
令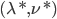 为对偶问题的解,则
为对偶问题的解,则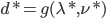 ;
; 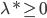 .
.
定理(弱对偶性):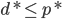 ,即对偶问题的优化值必然小于等于原问题优化值。
,即对偶问题的优化值必然小于等于原问题优化值。
6) 强对偶性
当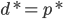 时,两者具有强对偶性;满足该条件的称之为constraint qualifications,如Sliter定理。
时,两者具有强对偶性;满足该条件的称之为constraint qualifications,如Sliter定理。
强对偶性满足的时候,原优化问题就可以化为一个二步优化问题了。
7) KTT条件(库恩-塔克条件)
局部最优化成立的必要条件:
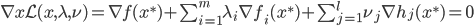 (一阶条件)
(一阶条件)
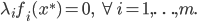
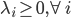
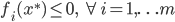
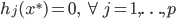
注:SVM满足强对偶性,所以可以直接解对偶问题。
2. 对偶问题应用于SVM
1) SVM的最优化问题
上节课可知,SVM的最优化问题为:
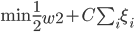
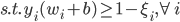
写成标准形式就是
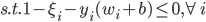
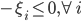
这样这里总计有2N个约束条件。
对应的Lagrange函数为:
这样一阶条件就是
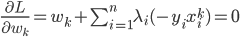
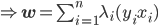
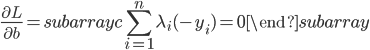
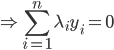
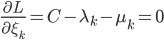
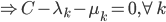
这样最后我们有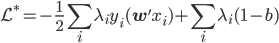 .
.
3) 对偶函数
这里的对偶函数就是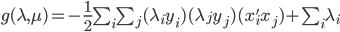
4) 对偶问题
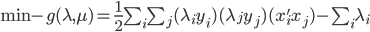
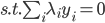
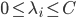
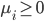
5) KKT条件
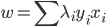
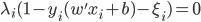
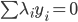
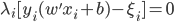
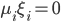
6) SVM分类器
- 解对偶问题,得到
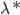 ,
, 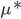
- 计算
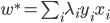
- 计算
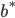 :找到一个
:找到一个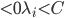 (非边界上),从而满足
(非边界上),从而满足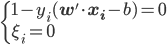 。由
。由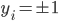 ,我们可得
,我们可得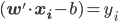

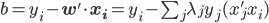
- 平面分类器:
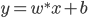 ,
, 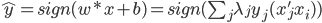 ,故只与内积有关。
,故只与内积有关。
这样下节课就会讲到解对偶问题的方法,以及SVM和kernel methods的联系。
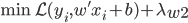
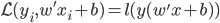 。
。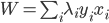
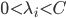 ,
,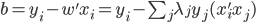 ,然后
,然后 。
。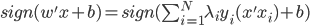
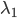 ,
,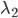 作为变量,其他
作为变量,其他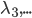 作为常量。
作为常量。
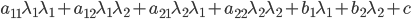
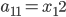 ,
,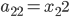 ,
,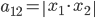 ,
,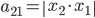 。
。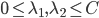 (对应对偶问题)
(对应对偶问题)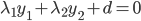 ,这里d代表其余不改变的那些
,这里d代表其余不改变的那些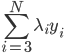 。
。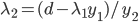
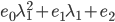 ,最优条件
,最优条件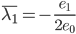
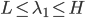 ,其中
,其中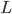 和
和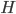 分别为lower/upper bound。故必有最优点在L、H之间或者L、H之一。
分别为lower/upper bound。故必有最优点在L、H之间或者L、H之一。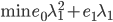 ,
,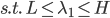 ,可以解得
,可以解得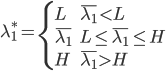
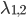 ,第一个变量
,第一个变量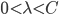 ,同时
,同时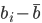 最大。第二个变量选择
最大。第二个变量选择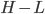 最大的。
最大的。