今儿继续读前几天说到的那本书:
Montgomery, Douglas (2013). Design and analysis of experiments (8th ed.). Hoboken, NJ: John Wiley & Sons, Inc. ISBN 9781118146927.
嗯,我读的很慢,唉,求轻拍啊。
刚读完第一章...(默默的跪墙角了,第一章才23页,居然读了这么久!)。看到一些比较有意思的点,抄一下顺便罗嗦一下。
1. 实验设计的原则
基本上就三点吧:随机化、重复、分块(blocking)。
- 随机化没什么好讲的了,就是保证treatment的分配和其他各种可观测不可观测的variable之间相互独立、相互不受干扰。从我的理解,这大概是源于一条定理(下为简述):
如果回归方程是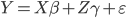 ,且
,且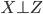 ,那么下面两式估计出来的
,那么下面两式估计出来的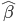 (均值)一致、估计方差后者小。
(均值)一致、估计方差后者小。
1)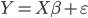
2)
所以如果我们保证了treatment和其他各种因素相互独立,就可以直接通过随机试验来读出treatment effect了。 - 重复。重复这里一方面可以广义的理解为“可重复研究”,另一方面其实很简单的就是样本量要足够(比如不停的抛硬币来判断硬币是不是均衡)。也就是说,只针对少数个体的实验可能受到各种随机外在因素的影响太大,而加大样本量(实验个体)有助于减少这样的误差、同时提高估计的精度。所以,重复更多的是,在相同(或者类似)的个体(情景)上重复同样的treatment/control。
- 分块。这个主要是排除一些样本间差异的影响。作者给的例子比较直接,有两批原料样本,然后做某种实验。两批原料可能由于批次、厂商不同,相互之间有些差别,但这种差别我们是不关心的。所以评估的时候,就把他们分开、每块单独评估。(或者理解为,回归方程里面加一个批次的dummy variable,然后算方差估计值的时候做一下cluster。
除上述三点之外,还有一个要注意的就是factorize,译作因子化?简单的来讲就是一分为二、是或者否。然后多个因子组合一下...
2. 实验设计的一些要点
这个就是高屋建瓴的说说咯。
- 利用自己在该领域的知识。否则就是盲测?感觉这个有点像经济学里面强调structual model的那种感觉...
- 实验设计和分析越简单越好。不是什么高深的技巧都应该一股脑的放在实验设计上的...越高深适应性可能就越差。
- 认识到实际价值和统计显著性。这个就是说,统计上显著的,实际中不一定有意思。比如花了很大力气,证明了某个treatment effect是显著的,但是提升只有0.01%,却增加10%的成本,那就得不偿失了。
- 实验往往是递进的。几乎没有一次性的实验是完美的,我们往往是在渐进的实验过程中不断学习。一般第一次实验都是简单而广泛的,更多是一种尝试和探索大致方向。作者建议不要把多余25%的资源投入到第一次实验。
嗯...其实挺好玩的还是,虽然有很多繁琐的地方,但大致的原则和方向还是蛮清晰的。实验设计其实最大的区别就是,不是想尽办法用模型去套现有的数据(黑一下ML),而是想办法更好的搜集数据、从而进一步时间简洁有力的分析(simple, elegant and powerful)。