前几天集中爆发了一些email,直到最后和Frank兄提起,他说我应该去看一下 Adaptive Lasso,我才终于痛下决心开始看这方面的东西。先说说为啥开始看Lasso。
需求。大数据时代,任务有很多:
- 理论层面,要有适应大数据的模型。一方面是数据量的增加(表现为个体记录的增长),一方面是数据维度的增加(简单的说就是回归方程右边的变量),让大数据这个任务变得格外艰巨(p.s. 这个不是我总结的,照抄上次ShanghaiR沙龙时候Ming的原话...话说我别的没记住,就这句话深深的印在脑海了,哎~)。
- 数据量的增加,对应的是大样本理论。这个好玩的有很多,暂且不表。
- 数据维数的增加,则需要相应的降维模型。你总不能在回归方程右边放入几千个变量,“维数灾难”啊...所以变量选择是个很好玩的话题。
- 应用层面,一个模型性质再漂亮,你也要能算得出来才行是不是?
- 首先就是要有个好的算法,比如在「统计学习那些事」中提及的LAR对于Lasso的巨大贡献。
- 其次,什么分布式计算啊,并行计算啊,都成为热呼呼的实践问题(当然我还是go against那些不管三七二十一、直接软件中调用模型的。任何一个模型的假设和局限性都是应该首先考虑的,要不真不知道预测到哪里去了呢~)。
好吧,好久没用这么多层级了。只是昨天稍稍理了理思路,顺便写在这里,算作「感悟一」。
然后,说到底统计学还是为其他学科服务的(好吧,我是想说数据不是无源之水,总归有自己的背景,总归有在这个背景领域的人希望借助数据来解决的问题)。那么作为一种empirical method,统计模型关心的是什么呢?在被计量经济学熏陶外加祸害了若干年后,发现它本质还是为了经济学研究的一些目的服务的,所以关注的更多是consistency,大家张口闭口就是“变量外生性”...而这多少有些直觉+经验判断的东西。显然,统计模型不仅仅是计量经济学,昨天看「The Elements of Statistical Learning: Data Mining, Inference, and Prediction」,大致的关于统计模型关心的判断标准的「感悟二」总结在这里:
- consistency:这个还是逃不掉的,一致性在大样本下虽然比小样本的无偏要求来的弱得多(plim毕竟比期望算子好“操作”一些)。其实有一段时间我一直很抵触把计量经济学里面的causality叫做因果关系,学习计量模型的过程基本就是保证估计一致性的推导过程...想说的只是,真正的因果关系不是统计学就可以定义的,还是要回到学科本身。consistency更多包含着“internal validity”的味道,即一个结果可以期望在样本本身内重复实现。个人感觉,从经济学理论与实证研究的角度,这大概是计量经济学能达到的最多的程度了吧。再苛刻的因果真的就是经济理论本身的问题了。
- accuracy: 统计还有一大任务,做预测。我们都知道OLS有的时候可以很简单的给出一个consistent的估计量,但是仅仅是均值意义上的估计还是不够的,对
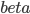 你还得给出个方差。这个方差就刻画了你的估计值是不是飘来飘去。我们当然希望一个方差比较小的估计量,所以大多数时候OLS是不能满足这样的要求的(顺便复习一下BLUE的那些条件)。
你还得给出个方差。这个方差就刻画了你的估计值是不是飘来飘去。我们当然希望一个方差比较小的估计量,所以大多数时候OLS是不能满足这样的要求的(顺便复习一下BLUE的那些条件)。
- implementable: 有的时候我们可以用现有的数据、花费大量的时间,来拟合一个漂亮的模型。但是,模型不是放在那里就可以的,在实际应用中大家更关心的是,模型建立之后对于日后决策的指导作用。可能1000个自变量拟合出来的模型比20个好10%到20%,但是在实际应用中,20个变量显然更实用...同理,有些非线性模型漂亮的一塌糊涂,但是计算复杂度可能远远不是多项式级别的。这个时候,退而求其次也不失为一记良策。说到底,有的时候并不要求最完美的模型,总要在性能和效率之间取得一个平衡。
- 当然说到prediction,这里更多的就有statistical learning的味道了。回归多少还算是supervised learning,至少脑海里大致有个印象什么是回归方程那一边的y。更多的时候,连y是什么都没有概念,所以就有了基于similarity的模型,比如clustering,比如协同过滤...不过有句话确实说的好(摘抄自「统计学习那些事」):
立新老师曾经有这么一句话:“If a method works well in practice, there must be some theoretical reasons for its success.” 如果一个模型在实践中表现的很好,那么一定有它好的原因。
所以基于上述三点(当然还有可能有更多的考虑),不同的模型对于不同的标准有着不同的达标水平。大家各有所长,用哪个还真得看实际任务的需求了。
「感悟三」,则是statistical learning (统计学习,有点机器学习的味道)的任务,这个是从「The Elements of Statistical Learning: Data Mining, Inference, and Prediction」上照抄的:
- 预测准确性要高:和上面的accuracy对应。
- 发现有价值的预测变量:更有可能从归纳法回溯到演绎法,给出更多的insights。
最后的,稍稍偏数学一点。「The Elements of Statistical Learning: Data Mining, Inference, and Prediction」里面第三章讲了很多Shrinkage Methods,关心的是varible selection(生物统计中feature selection)的问题。从大家最耳熟能详的stepwise(逐步回归),到ridge regression(岭回归),再到Lasso(或者把LAR也算进来)。基本说来,ridge和Lasso是在OLS基础上一个很有意思的变化。
- OLS求解的最优化问题是:
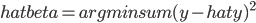
- ridge regression则是加了一个L2惩罚项,即
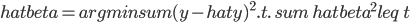 ,其中t是一个给定常数参数。
,其中t是一个给定常数参数。
- Lasso则是把这个L2变成了L1,即
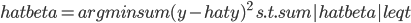
就这么一个简简单单的变化,就有了后面那么多神奇的性质。「感悟四」就是,原来Lasso思想并不是那么复杂啊。