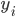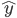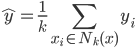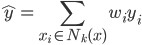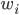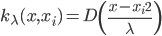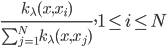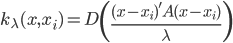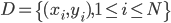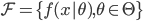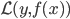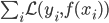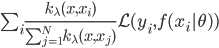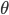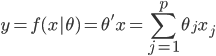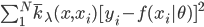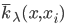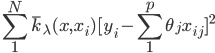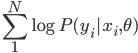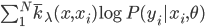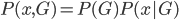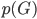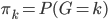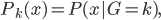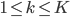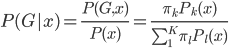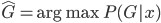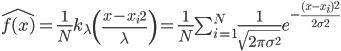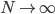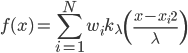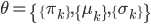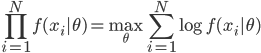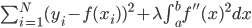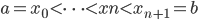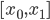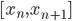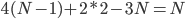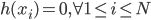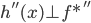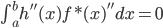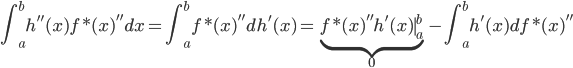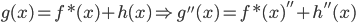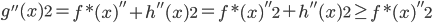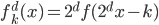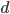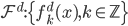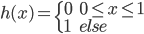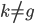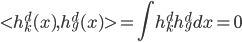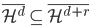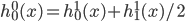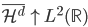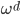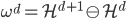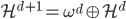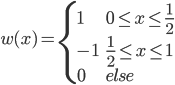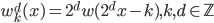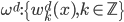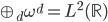这个话题可以很深,我这里只是随便写写。当然我也不去定义什么是“新媒体”了...基本上下面可以视之为社交网络媒体。此文纯属若干无知的随便念叨,内行请无视。
记得原来在做社会实验的时候,最头疼的就是网络效应——这东西会让你的随机分组失效。如果网络扩散是均匀的也就罢了,这东西还不均匀,搞得随机分组基本上被破坏殆尽。今天和做社会网络营销这块儿同事聊起,发现他们在新媒体营销上也是遇到了类似的问题——传统的A/B test基本失效,因为control组会被极大程度的“污染”。和电视营销的地理隔离还不一样,社交网络是无孔不入的...
但是偏偏,我们还是希望可以利用这样的网络效应的——主动的传播岂不是更好?于是问题就变成了如何去精准衡量网络效应。
从我们以前的做法(可以参见我的硕士论文,in English),基本上是需要动用IV的...哎,然后这个IV还其难找无比。有些幸运的情况,IV是可以找到的,但是也需要一些外在的shock强行的打破现有的网络连接。
如果说要找一种比较简单的做法,那可能就是类似于spatial econometrics他们做的那样,对各个个体在空间中的位置进行加权。比如你要衡量微博营销的ROI,肯定要跟踪到实际覆盖的个体,然后在构造了网络结构的基础上,对个体的位置进行加权。但是讨厌的是,位置或者连接这些东西都是内生的...所以需要去找自然实验,然后去找工具变量...
总而言之,在我读过的为数不多的paper里面,可以很好的衡量网络效应的很少,而那些极少的还是控制了可控的资源的(比如实际的物品发放而不是新闻式传播)。感觉受新媒体的影响和冲击,很多传统的营销方式都在面临着极大的变化,做的好的往往不是分析人员算出来的而更多的是营销人员一步步摸索出来的...
所以,其实我想说的是,可能需要增加一些更好使用的指标来衡量新媒体营销的力量,而不是期待更好的分析方法的改进来支撑营销。后者还需时间来打磨(如果不是case by case的找IV的话)...