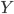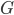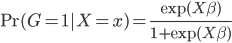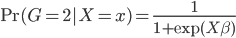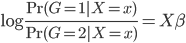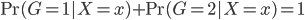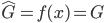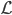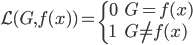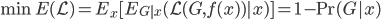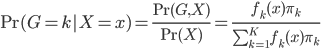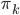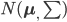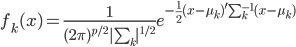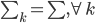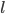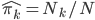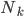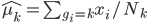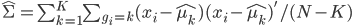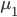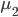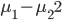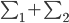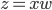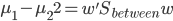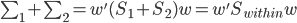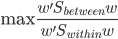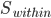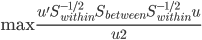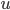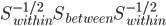前几天跟家父闲扯,说到我这辈子为数不多后悔的事情,就是本科选专业没选数学。我的性子基本上是不会多想过去已经发生的不可改变的事情的,所以人生中还真没多少后悔的事。这件事情是例外,是因为从毕业以来一直在为其还债,不得不怨念一下。当然,确实很难讲如果我当时学了数学,现在会不会过得更好。可能也不会。
假设过去未曾发生的事情没什么意义,不如讲讲为什么让我这么怨念。前几天在查一个模型,想知道一些大样本特性那边的结论,于是开始翻看相关的论文。结果论文读着读着就读不下去了,因为根本看不懂其中的引理。不仅仅是证明看不懂,而是根本不知道为什么要用到这些引理,这就很尴尬了是不?回头查了查,这些基础知识都是渐进理论那边的,属于概率论吧,确实没有学过,不知道就是不知道。
这种捉襟见肘的感觉实在是太熟悉了。去年看另外一个方向的论文,发现根本没学过concentration相关理论(这个名词不翻译了),然后现学现卖,抓紧去补那块儿的知识。然后看到Lipschitz 连续性,完全不记得实分析怎么讲的了,又得回头复习。为什么不记得呢,还是因为当年没理解,没有把数学融会贯通成自己的思维,自然考完试就忘了。不过至少因为学过,所以复习总是比重新学习容易一些,而且这次看到应用了也能加深对其本身的理解。数学虽说是个工具,但是如果不记得工具怎么来的可以怎么用,那要么就只能望洋兴叹,要么就闭着眼瞎用。鉴于后者着实不是我的风格,大部分时间我都只能止步之后扼腕叹息。
说到底,之所以数学让我这么痛苦,还是很多东西学的时候没有成体系,用到什么补什么。像微积分啊线性代数啊这种还好,宏微观计量各来一遍,到后面怎么也不会忘了。但是其他的不常用的就惨了, 只能两眼一抹黑,实在不行就死记硬背吧。我挺佩服那些随时可以从一个阶段捡起数学直接用的人,他们不需要知道下面的基础是怎么架构的,只需要往上盖就行。我受不了这样,对我来说数学一定是一以贯之的,若是我不曾理解基础那我就永远没法继续往下走。当然我可能不会一直记得每一个细节是怎么样子,但大体的脉络永远是清晰的。
可能事情并没有我想象的那么糟,我的数学知识也不是哪里都是窟窿永远填不完。但这种不知道我还有多少窟窿没填的状态,让我大部分时间都没有底气,特别惧怕又发现一个窟窿那种沮丧感。毕竟一直处于一种“追赶”的感觉会让人自信全无。若是曾经在本科阶段按部就班地训练过,或许就不会像现在这样不安了。比如看经济学我就不会不安,因为我知道自己的基础很牢,一切新生事物都是基于以往一些问题的拓展,这给了我很足的底气来辩证地学习新知识(以及看到胡说八道的理论知道他们是在胡说八道)。正是因为有这两者完全不一样的状态的对比,我才无法控制自己的怨念。
======
题外话,本科专业没选数学完全是当时的无知。按说我一个高中生无知就罢了,我得到的各种指导信息居然都是,“大学数学和高中数学不是一回事儿,高中数学再好大学数学都有可能让你失去兴趣。”之类。居然没有一个人告诉我数学本身对于其他基础科学是有多么重要。感觉数学教育出了很大问题,让前面学过数学的人并没有体会到数学的基础性和重要性,自然也就无法告知后来者。当然,从家父的角度,他觉得稳妥最重要,数学一看就是一个找不到工作的专业。我不否认,从现在来看确实很多数学专业学着学着就走进死胡同了。但更重要的是,我的性格决定我并不会安于现状,而除了数学之外,怕是少有一直能给我足够的智力挑战的东西了。那种从抽象层面理解事物的满足感,那种一脉相承融会贯通的舒畅感,至今不曾从别的事物上体验过。性格决定命运,所以虽然对于大多数人来说,本科学数学或许并不是一件好事,但对于我来说,却导致了十几年来的最大缺憾。