本系列连载文章:
在SAS各种繁杂的PROC之后,还要来看看MACRO才可以嘛。又不能写函数...
SAS中的MACRO:宏编写
MACRO主要是DO和%LET的各种组合,前者负责循环后者负责变量。
一个例子:
%LET flowertype = Ginger;
* Read the data and subset with a macro variable;
DATA flowersales;
INFILE 'c:\MyRawData\TropicalSales.dat';
INPUT CustomerID $4. @6 SaleDate MMDDYY10. @17 Variety $9. Quantity;
IF Variety = "&flowertype";
RUN;
* Print the report using a macro variable;
PROC PRINT DATA = flowersales;
FORMAT SaleDate WORDDATE18.;
TITLE "Sales of &flowertype";
RUN;
这段代码可以做什么呢?很简单,替换文字。我们指定了一个SAS MACRO中的变量flowertype,在执行MACRO的时候他会被自动翻译成标准的SAS代码。这样执行的结果就是:
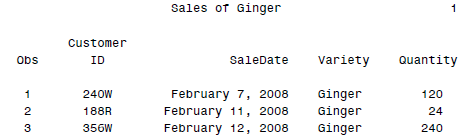
看到了吧,标题已经被替换了。
一段MACRO以%macro开始,然后以%mend结束。
* Macro to print 5 largest sales;
%MACRO sample;
PROC SORT DATA = flowersales;
BY DESCENDING Quantity;
RUN;
PROC PRINT DATA = flowersales (OBS = 5);
FORMAT SaleDate WORDDATE18.;
TITLE 'Five Largest Sales';
RUN;
%MEND sample;
* Read the flower sales data;
DATA flowersales;
INFILE 'c:\MyRawData\TropicalSales.dat';
INPUT CustomerID $4. @6 SaleDate MMDDYY10. @17 Variety $9. Quantity;
RUN;
* Invoke the macro;
%sample
这样执行之后的结果就是:
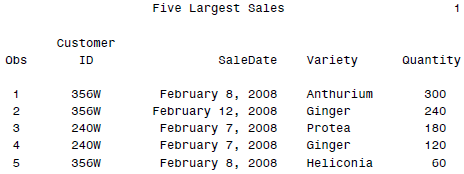
虽然SAS不可以直接写函数,但是MACRO还是有参数可以传入的。
* Macro with parameters;
%MACRO select(customer=,sortvar=);
PROC SORT DATA = flowersales OUT = salesout;
BY &sortvar;
WHERE CustomerID = "&customer";
RUN;
PROC PRINT DATA = salesout;
FORMAT SaleDate WORDDATE18.;
TITLE1 "Orders for Customer Number &customer";
TITLE2 "Sorted by &sortvar";
RUN;
%MEND select;
* Read all the flower sales data;
DATA flowersales;
INFILE 'c:\MyRawData\TropicalSales.dat';
INPUT CustomerID $4. @6 SaleDate MMDDYY10. @17 Variety $9. Quantity;
RUN;
*Invoke the macro;
%select(customer = 356W, sortvar = Quantity)
%select(customer = 240W, sortvar = Variety)
这样传入的参数会自动作为变量被替换掉。结果如下:
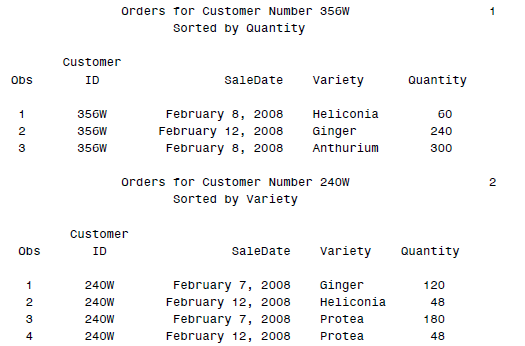
当然MACRO中也会有需要判断的时候,这就是IF上场之时啦:
%MACRO dailyreports;
%IF &SYSDAY = Monday %THEN %DO;
PROC PRINT DATA = flowersales;
FORMAT SaleDate WORDDATE18.;
TITLE 'Monday Report: Current Flower Sales';
RUN;
%END;
%ELSE %IF &SYSDAY = Tuesday %THEN %DO;
PROC MEANS DATA = flowersales MEAN MIN MAX;
CLASS Variety;
VAR Quantity;
TITLE 'Tuesday Report: Summary of Flower Sales';
RUN;
%END;
%MEND dailyreports;
DATA flowersales;
INFILE 'c:\MyRawData\TropicalSales.dat';
INPUT CustomerID $4. @6 SaleDate MMDDYY10. @17 Variety $9. Quantity;
RUN;
%dailyreports
比如周二,那么翻译出来的SAS代码就是:
DATA flowersales;
INFILE 'c:\MyRawData\TropicalSales.dat';
INPUT CustomerID $ @6 SaleDate MMDDYY10. @17 Variety $9. Quantity;
RUN;
PROC MEANS DATA = flowersales MEAN MIN MAX;
CLASS Variety;
VAR Quantity;
TITLE 'Tuesday Report: Summary of Flower Sales';
RUN;
最终得到的结果为:
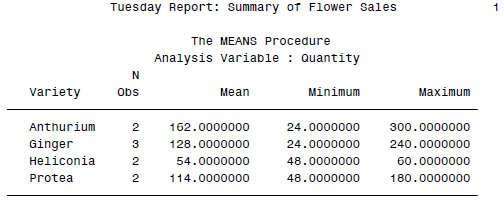
SAS中使用CALL SYMPUT:用数据值赋予变量
如果有的时候需要数据集中的值来给MACRO中的变量赋值,我们就需要使用CALL SYMPUT了。
* Read the raw data;
DATA flowersales;
INFILE 'c:\MySASLib\TropicalSales.dat';
INPUT CustomerID $4. @6 SaleDate MMDDYY10. @17 Variety $9. Quantity;
PROC SORT DATA = flowersales;
BY DESCENDING Quantity;
RUN;
* Find biggest order and pass the customer id to a macro variable;
DATA _NULL_;
SET flowersales;
IF _N_ = 1 THEN CALL SYMPUT("selectedcustomer",CustomerID);
ELSE STOP;
RUN;
PROC PRINT DATA = flowersales;
WHERE CustomerID = "&selectedcustomer";
FORMAT SaleDate WORDDATE18.;
TITLE "Customer &selectedcustomer Had the Single Largest Order";
RUN;
这样的结果就成了:
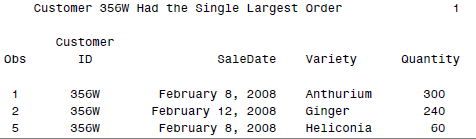
看出来这里面的逻辑了么?我们先对数据集flowersales进行了排序,然后选择第一名的订单用户,赋值给selectedcustomer这个变量,然后就可以直接在后面用&selectedcustomer调用这个变量值,去查找属于他的观测记录了。
SAS MACRO的DEBUG调试
这里就是一些基本的找错技巧了:
- 避免最常见的语法错误:先写一般的SAS语句,然后去替换需要用到变量的部分。
- 引号问题:如果用单引号,那么SAS不会替换里面的变量值;如果用双引号,那么里面&variable的值会被替换掉。所以酌情注意。
- SAS的报错记录:有MERROR(找不到macro)、SERROR(找不到变量)、MLOGIC(SAS将在日志中输出详细的执行情况)、MPRINT(SAS将在日志中输出翻译出来的SAS代码)、SYMBOLGEN(SAS将在日志中输出变量当时的赋值)。
SAS常见程序错误
最常见的大概就是少了结尾的分号...这里的报错一般是:
ERROR 180-322: Statement is not valid or it is used out of proper order.
或者其他类似的语句无法被SAS理解的。
还有就是输入数据不正确或者有缺失值什么的...这个我觉得在数据源是数据库管理系统的时候,不是什么问题...
还有就是数值型被转换成文本型...报错类似于:
NOTE: Character values have been converted to numeric values at the places
given by:(Line):(Column).
我们利用PUTLOG可以一步步的输出SAS计算的过程:
9 * Keep only students with mean below 70;
10 DATA lowscore;
11 INFILE ’c:MyRawDataClass.dat’;
12 INPUT Name $ Score1 Score2 Score3 Homework;
13 Homework = Homework * 2;
14 AverageScore = MEAN(Score1 + Score2 + Score3 + Homework);
15 PUTLOG Name= Score1= Score2= Score3= Homework= AverageScore=;
16 IF AverageScore < 70;
17 RUN;
这样也有利于查错。
其他的可以直接看报错信息来判断,不赘述了。
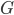 来代替
来代替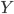 作为观测到的分类结果,那么则有:
作为观测到的分类结果,那么则有: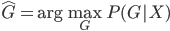 为最优的预测结果。这里我们希望找到一种线性的形式,还需要使用一些单调变换保证预测值在
为最优的预测结果。这里我们希望找到一种线性的形式,还需要使用一些单调变换保证预测值在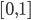 之间。因此,我们对于每个分类
之间。因此,我们对于每个分类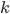 ,假设
,假设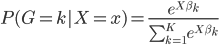
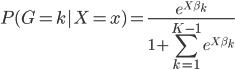 且
且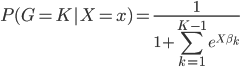
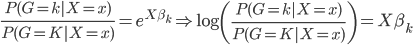
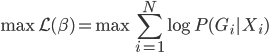
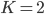 为例,来展示求解过程。
为例,来展示求解过程。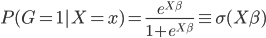
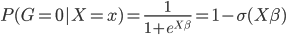 则它的对数似然函数:
则它的对数似然函数:
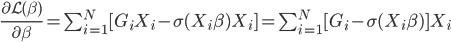
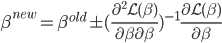
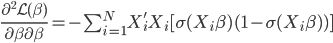
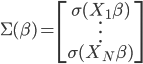
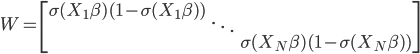
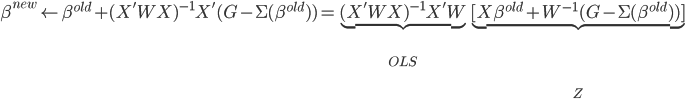
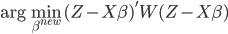
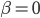 或任意起始值
或任意起始值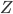 矩阵.
矩阵.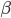 为
为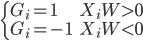
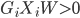
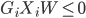 ,出错。
,出错。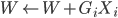 ,重复第一步。
,重复第一步。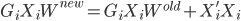 ,一定是在逐步增加的。
,一定是在逐步增加的。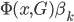 ,使得条件概率
,使得条件概率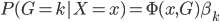 。这样我们的目标就是找到
。这样我们的目标就是找到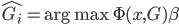
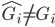 时,
时,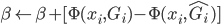 ,直至收敛。
,直至收敛。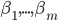 的平均值效果会更好,而不是最终的
的平均值效果会更好,而不是最终的

 to the OUTEST= data set
to the OUTEST= data set