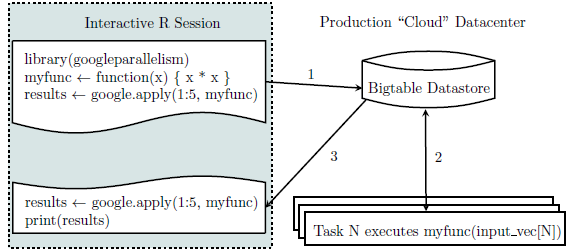
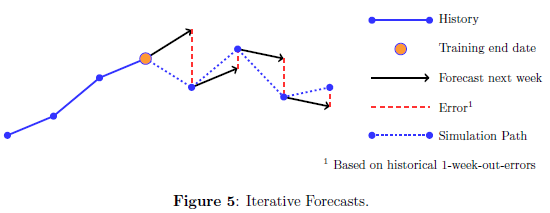
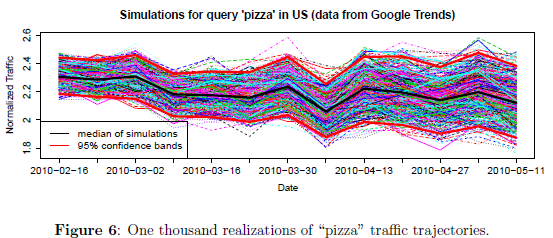
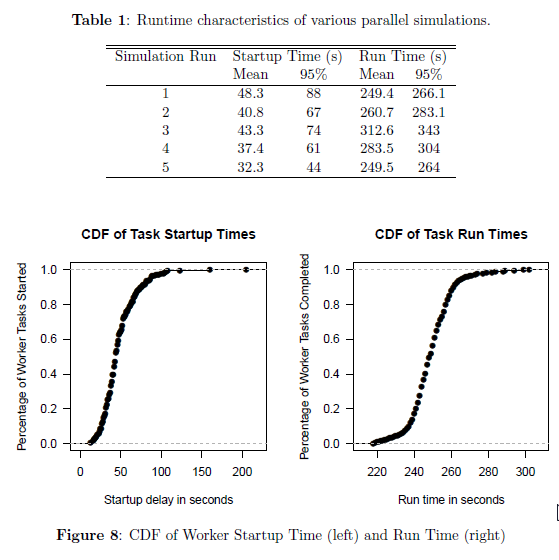
标题有些噱头,不过这里的重点是: speak SAS in 7 days。也就是说,知识是现成的,我这里只是要学会如何讲这门语言,而不是如何边学SAS边学模型。顺便发现我最近喜欢写连载了,自从西藏回来后.....
之所以下定决定学SAS,是因为周围的人都在用SAS。为了和同事的沟通更有效率,还是多学一门语言吧。R再灵活,毕竟还是只有少数人能直接读懂。理论上语言是不应该成为障碍的~就像外语一样,多学一点总是好的,至少出门不发怵是不是?
最后一根稻草则是施老师传给我的一个link:http://blog.softwareadvice.com/articles/bi/3-career-secrets-for-data-scientists-1101712/,据说有数据分析师的职业秘笈...我就忍不住去看了看。其中一句话还是蛮有启发的:
如果有人问你要学什么工具,是SAS,R,EXCEL,SQL,SPSS还是?直接回答:所有。
这个答案一方面霸气,一方面也是,何必被工具束缚呢?
这东西宜突击不宜拖延,所以还是集中搞定吧。七天应该是个不错的时间段。
大致分配如下:
1. 熟悉SAS的数据结构,如基本的向量,数据集,数组;熟悉基本的数据类型,如文本,数字。
2. 熟悉基本的数据输入与输出。
3. 熟悉基本的逻辑语句:循环,判断
4. 熟悉基本的数据操作:筛选行列,筛选或计算变量,合并数据集,计算基本统计量,转置
5. 熟悉基本的文本操作函数
6. 熟悉基本的计量模型函数
7. 熟悉基本的macro编写,局部变量与全局变量
其实这大概也是按照我常用的R里面完成的任务来罗列的。基本计划是完成就可以大致了解SAS的语法了,其他的高级功能现用现学吧。
书籍方面,中文的抢了同事的一本《SAS编程与数据挖掘商业案例》,英文的找了一本「Applied Econometrics Using The SAS System」和「The Little SAS Book」,先这么看着吧。
后知后觉的补充:其实这一系列笔记都是先写再发布的,主要是方便我调整顺序什么的。事实证明绝大多数时间我在看(或者更直接的,抄)「The Little SAS Book」这本书,姚老师的《SAS编程与数据挖掘商业案例》简单看了一晚,作为对于SAS语法的预热。最后那本「Applied Econometrics Using The SAS System」更多是看具体模型的用法了,不是熟悉语法的问题了。例子都是第一本little book上的,很好用。
本系列连载文章:
- 七天搞定SAS(七):常用统计模型
- 七天搞定SAS(六):宏的编写、程序调错
- 七天搞定SAS(五):数据操作与合并
- 七天搞定SAS(四):数据输出
- 七天搞定SAS(三):基本模块调用(格式、计数、概要统计、排序等)
- 七天搞定SAS(二):基本操作(判断、运算、基本函数)
- 七天搞定SAS(一):数据的导入、数据结构
-------笔记开始-------
SAS的数据类型

首先,sas的编程大概就两块:Data和PROC,这个倒是蛮清晰的划分。然后目前关注data部分。
SAS的数据类型还真的只有两种:数字和文本。那么看来日期就要存成文本型了。变量名称后面加$代表文本型。
SAS的数据读入
手动输入这种就不考虑了,先是怎么从本地文件读入。比如我们有文本文件如下:
Lucky 2.3 1.9 . 3.0 Spot 4.6 2.5 3.1 .5 Tubs 7.1 . . 3.8 Hop 4.5 3.2 1.9 2.6 Noisy 3.8 1.3 1.8 1.5 Winner 5.7 . . .
然后SAS里面就可以用
* Create a SAS data set named toads; * Read the data file ToadJump.dat using list input; DATA toads; INFILE ’c:\MyRawData\ToadJump.dat’; INPUT ToadName $ Weight Jump1 Jump2 Jump3; RUN; * Print the data to make sure the file was read correctly; PROC PRINT DATA = toads; TITLE ’SAS Data Set Toads’; RUN;
这样就建立了一个名为toads的临时数据集,然后读入外部文件ToadJump.dat,然后告诉SAS有四个变量,其中第一个是文本型。这样就OK了。缺失值用一个点.标记。
偶尔数据没那么规范,比如长成:
----+----1----+----2----+----3----+----4 Columbia Peaches 35 67 1 10 2 1 Plains Peanuts 210 2 5 0 2 Gilroy Garlics 151035 12 11 7 6 Sacramento Tomatoes 124 85 15 4 9 1
那么就要有点类似正则表达式的感觉,告诉SAS更多的参数:
* Create a SAS data set named sales; * Read the data file OnionRing.dat using column input; DATA sales; INFILE ’c:\MyRawData\OnionRing.dat’; INPUT VisitingTeam $ 1-20 ConcessionSales 21-24 BleacherSales 25-28 OurHits 29-31 TheirHits 32-34 OurRuns 35-37 TheirRuns 38-40; RUN; * Print the data to make sure the file was read correctly; PROC PRINT DATA = sales; TITLE ’SAS Data Set Sales’; RUN;
这样SAS就可以正确的读数据了—类似于excel的导入文本-固定宽度分隔。
再不规则的话,比如有日期型的:
Alicia Grossman 13 c 10-28-2008 7.8 6.5 7.2 8.0 7.9 Matthew Lee 9 D 10-30-2008 6.5 5.9 6.8 6.0 8.1 Elizabeth Garcia 10 C 10-29-2008 8.9 7.9 8.5 9.0 8.8 Lori Newcombe 6 D 10-30-2008 6.7 5.6 4.9 5.2 6.1 Jose Martinez 7 d 10-31-2008 8.9 9.510.0 9.7 9.0 Brian Williams 11 C 10-29-2008 7.8 8.4 8.5 7.9 8.0
那么接下来就是:
* Create a SAS data set named contest; * Read the file Pumpkin.dat using formatted input; DATA contest; INFILE ’c:\MyRawData\Pumpkin.dat’; INPUT Name $16. Age 3. +1 Type $1. +1 Date MMDDYY10. (Score1 Score2 Score3 Score4 Score5) (4.1); RUN; * Print the data set to make sure the file was read correctly; PROC PRINT DATA = contest; TITLE ’Pumpkin Carving Contest’; RUN;
就是说,name是一个长度为16的字符;age是长度为3、无小数点的数字;+1跳过空列;type是长度为1的文本;date是MMDDYY长度为10的日期;score1-5是长度为4,小数部分为1位的数字。
还有若干更复杂的,可以遇到时侯回来查手册。此外还有@可用来直接指定开始读的列。鉴于我接触的数据一般比较规范,这些就不细看了。
此外SAS可以指定开始读的行数,读取的行数等。
DATA icecream; INFILE ’c:\MyRawData\IceCreamSales.dat’ FIRSTOBS = 3; INPUT Flavor $ 1-9 Location BoxesSold; RUN;
SAS读取CSV数据
以我最关心的CSV文件为例,如下数据:
Lupine Lights,12/3/2007,45,63,70, Awesome Octaves,12/15/2007,17,28,44,12 "Stop, Drop, and Rock-N-Roll",1/5/2008,34,62,77,91 The Silveyville Jazz Quartet,1/18/2008,38,30,42,43 Catalina Converts,1/31/2008,56,,65,34
只需要:
DATA music; INFILE ’c:\MyRawData\Bands.csv’ DLM = ’,’ DSD MISSOVER; INPUT BandName :$30. GigDate :MMDDYY10. EightPM NinePM TenPM ElevenPM; RUN; PROC PRINT DATA = music; TITLE ’Customers at Each Gig’; RUN;
其实,貌似更简单的办法是:
DATA music; INFILE ’c:\MyRawData\Bands.csv’ DLM = ’,’ DSD MISSOVER; INPUT BandName :$30. GigDate :MMDDYY10. EightPM NinePM TenPM ElevenPM; RUN; PROC PRINT DATA = music; TITLE ’Customers at Each Gig’; RUN;
好吧,import果然更直接一点...excel文件也可以如法炮制。
SAS读取excel数据
* Read an Excel spreadsheet using PROC IMPORT; PROC IMPORT DATAFILE = 'c:\MyExcelFiles\OnionRing.xls' DBMS=XLS OUT = sales; RUN; PROC PRINT DATA = sales; TITLE 'SAS Data Set Read From Excel File'; RUN;
如果需要SAS永久存着这些数据,则需要先指定libname:
LIBNAME plants ’c:\MySASLib’; DATA plants.magnolia; INFILE ’c:\MyRawData\Mag.dat’; INPUT ScientificName $ 1-14 CommonName $ 16-32 MaximumHeight AgeBloom Type $ Color $; RUN;
后期就可以直接调用啦:
LIBNAME example ’c:\MySASLib’; PROC PRINT DATA = example.magnolia; TITLE ’Magnolias’; RUN;
SAS 读取Teradata数据
最后就是从teradata里面读数据,可以利用teradata fastexport特性:
libname tra Teradata user=terauser pw=XXXXXX server=boom; proc freq data=tra.big(dbsliceparm=all); table x1-x3; run;
等价于:
proc sql; connect to teradata(user=terauser password=XXXXXX server=boom dbsliceparm=all); select * from connection to teradata (select * from big); quit;
暂时没有fastload的需求,就先这样吧。可以参见SAS的TD手册:http://support.sas.com/resources/papers/teradata.pdf
本系列连载文章:
- 七天搞定SAS(七):常用统计模型
- 七天搞定SAS(六):宏的编写、程序调错
- 七天搞定SAS(五):数据操作与合并
- 七天搞定SAS(四):数据输出
- 七天搞定SAS(三):基本模块调用(格式、计数、概要统计、排序等)
- 七天搞定SAS(二):基本操作(判断、运算、基本函数)
- 七天搞定SAS(一):数据的导入、数据结构